Databricks Databricks Certified Data Engineer Professional Übungsprüfungen
Zuletzt aktualisiert am 08.03.2026- Prüfungscode: Databricks Certified Data Engineer Professional
- Prüfungsname: Databricks Certified Data Engineer Professional Exam
- Zertifizierungsanbieter: Databricks
- Zuletzt aktualisiert am: 08.03.2026
The Databricks workspace administrator has configured interactive clusters for each of the data engineering groups. To control costs, clusters are set to terminate after 30 minutes of inactivity. Each user should be able to execute workloads against their assigned clusters at any time of the day.
Assuming users have been added to a workspace but not granted any permissions, which of the following describes the minimal permissions a user would need to start and attach to an already configured cluster.
- A . "Can Manage" privileges on the required cluster
- B . Workspace Admin privileges, cluster creation allowed. "Can Attach To" privileges on the required cluster
- C . Cluster creation allowed. "Can Attach To" privileges on the required cluster
- D . "Can Restart" privileges on the required cluster
- E . Cluster creation allowed. "Can Restart" privileges on the required cluster
What is the correct way to handle parameter passing through the Databricks Jobs API for date variables in scheduled notebooks?
- A . date = spark.conf.get("date")
- B . input_dict = input(); date = input_dict["date"]
- C . import sys; date = sys.argv[1]
- D . date = dbutils.notebooks.getParam("date")
What is the correct way to handle parameter passing through the Databricks Jobs API for date variables in scheduled notebooks?
- A . date = spark.conf.get("date")
- B . input_dict = input(); date = input_dict["date"]
- C . import sys; date = sys.argv[1]
- D . date = dbutils.notebooks.getParam("date")
The business reporting tem requires that data for their dashboards be updated every hour. The total processing time for the pipeline that extracts transforms and load the data for their pipeline runs in 10 minutes.
Assuming normal operating conditions, which configuration will meet their service-level agreement requirements with the lowest cost?
- A . Schedule a jo to execute the pipeline once and hour on a dedicated interactive cluster.
- B . Schedule a Structured Streaming job with a trigger interval of 60 minutes.
- C . Schedule a job to execute the pipeline once hour on a new job cluster.
- D . Configure a job that executes every time new data lands in a given directory.
Which statement describes integration testing?
- A . Validates interactions between subsystems of your application
- B . Requires an automated testing framework
- C . Requires manual intervention
- D . Validates an application use case
- E . Validates behavior of individual elements of your application
To monitor temperatures via a Databricks SQL query and create alerts, the trigger condition for an alert is based on:
- A . The maximum temperature across all sensors
- B . The average temperature across all sensors
- C . The minimum temperature across any sensor
- D . The average temperature for at least one sensor
A table named user_ltv is being used to create a view that will be used by data analysis on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
The user_ltv table has the following schema:

An analyze who is not a member of the auditing group executing the following query:
![]()
Which result will be returned by this query?
- A . All columns will be displayed normally for those records that have an age greater than 18; records not meeting this condition will be omitted.
- B . All columns will be displayed normally for those records that have an age greater than 17; records not meeting this condition will be omitted.
- C . All age values less than 18 will be returned as null values all other columns will be returned with the values in user_ltv.
- D . All records from all columns will be displayed with the values in user_ltv.
The data engineering team maintains the following code:
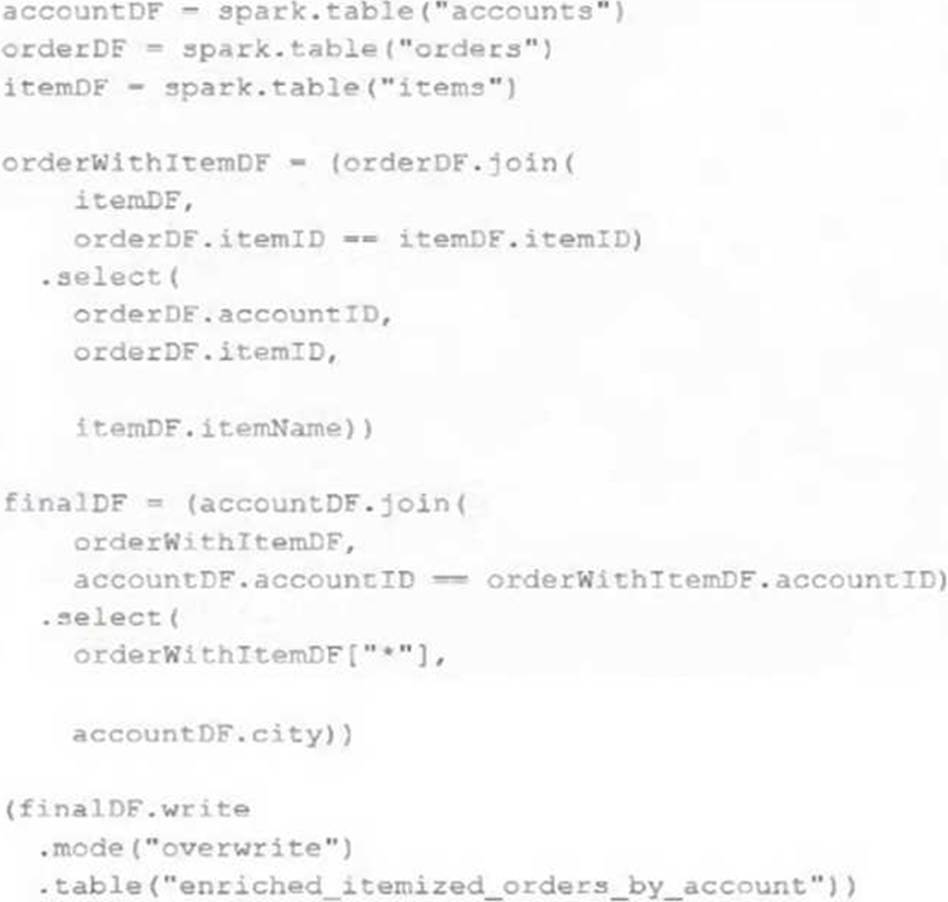
Assuming that this code produces logically correct results and the data in the source tables has been de-duplicated and validated, which statement describes what will occur when this code is executed?
- A . A batch job will update the enriched_itemized_orders_by_account table, replacing only those rows that have different values than the current version of the table, using accountID as the primary key.
- B . The enriched_itemized_orders_by_account table will be overwritten using the current valid version of data in each of the three tables referenced in the join logic.
- C . An incremental job will leverage information in the state store to identify unjoined rows in the source tables and write these rows to the enriched_iteinized_orders_by_account table.
- D . An incremental job will detect if new rows have been written to any of the source tables; if new rows are detected, all results will be recalculated and used to overwrite the enriched_itemized_orders_by_account table.
- E . No computation will occur until enriched_itemized_orders_by_account is queried; upon query materialization, results will be calculated using the current valid version of data in each of the three tables referenced in the join logic.
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
MERGE INTO customers
USING (
SELECT updates.customer_id as merge_ey, updates .*
FROM updates
UNION ALL
SELECT NULL as merge_key, updates .*
FROM updates JOIN customers
ON updates.customer_id = customers.customer_id
WHERE customers.current = true AND updates.address <> customers.address ) staged_updates
ON customers.customer_id = mergekey
WHEN MATCHED AND customers. current = true AND customers.address <> staged_updates.address
THEN
UPDATE SET current = false, end_date = staged_updates.effective_date
WHEN NOT MATCHED THEN
INSERT (customer_id, address, current, effective_date, end_date) VALUES (staged_updates.customer_id, staged_updates.address, true, staged_updates.effective_date, null)
Which statement describes this implementation?
- A . The customers table is implemented as a Type 2 table; old values are overwritten and new customers are appended.
- B . The customers table is implemented as a Type 1 table; old values are overwritten by new values and no history is maintained.
- C . The customers table is implemented as a Type 2 table; old values are maintained but marked as no longer current and new values are inserted.
- D . The customers table is implemented as a Type 0 table; all writes are append only with no changes to existing values.
A data engineer, User A, has promoted a new pipeline to production by using the REST API to programmatically create several jobs. A DevOps engineer, User B, has configured an external orchestration tool to trigger job runs through the REST API. Both users authorized the REST API calls using their personal access tokens.
Which statement describes the contents of the workspace audit logs concerning these events?
- A . Because the REST API was used for job creation and triggering runs, a Service Principal will be automatically used to identity these events.
- B . Because User B last configured the jobs, their identity will be associated with both the job creation
events and the job run events. - C . Because these events are managed separately, User A will have their identity associated with the job creation events and User B will have their identity associated with the job run events.
- D . Because the REST API was used for job creation and triggering runs, user identity will not be captured in the audit logs.
- E . Because User A created the jobs, their identity will be associated with both the job creation events and the job run events.