Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 05.04.2026- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 05.04.2026
You are building a data flow in Azure Data Factory that upserts data into a table in an Azure Synapse Analytics dedicated SQL pool.
You need to add a transformation to the data flow. The transformation must specify logic indicating when a row from the input data must be upserted into the sink.
Which type of transformation should you add to the data flow?
- A . join
- B . select
- C . surrogate key
- D . alter row
You are designing a folder structure for the files m an Azure Data Lake Storage Gen2 account. The account has one container that contains three years of data.
You need to recommend a folder structure that meets the following requirements:
• Supports partition elimination for queries by Azure Synapse Analytics serverless SQL pooh
• Supports fast data retrieval for data from the current month
• Simplifies data security management by department
Which folder structure should you recommend?
- A . YYYMMDDDepartmentDataSourceDataFile_YYYMMMDD.parquet
- B . DepdftmentDataSourceYYYMMDataFile_YYYYMMDD.parquet
- C . DDMMYYYYDepartmentDataSourceDataFile_DDMMYY.parquet
- D . DataSourceDepartmentYYYYMMDataFile_YYYYMMDD.parquet
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast columns to specified types of data, and insert the data into a table in an Azure Synapse Analytic dedicated SQL pool. The CSV file contains three columns named username, comment, and date.
The data flow already contains the following:
✑ A source transformation.
✑ A Derived Column transformation to set the appropriate types of data.
✑ A sink transformation to land the data in the pool.
You need to ensure that the data flow meets the following requirements:
✑ All valid rows must be written to the destination table.
✑ Truncation errors in the comment column must be avoided proactively.
✑ Any rows containing comment values that will cause truncation errors upon insert must be written to a file in blob storage.
Which two actions should you perform? Each correct answer presents part of the solution . NOTE: Each correct selection is worth one point.
- A . To the data flow, add a sink transformation to write the rows to a file in blob storage.
- B . To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
- C . To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
- D . Add a select transformation to select only the rows that will cause truncation errors.
You have an Azure subscription that contains an Azure Blob Storage account named storage1 and an Azure Synapse Analytics dedicated SQL pool named Pool1.
You need to store data in storage 1. The data will be read by Pool 1.
The solution must meet the following requirements:
✑ Enable Pool1 to skip columns and rows that are unnecessary in a query.
✑ Automatically create column statistics.
✑ Minimize the size of files.
Which type of file should you use?
- A . JSON
- B . Parquet
- C . Avro
- D . CSV
You have an Azure Stream Analytics query. The query returns a result set that contains 10,000 distinct values for a column named clusterID.
You monitor the Stream Analytics job and discover high latency.
You need to reduce the latency.
Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . Add a pass-through query.
- B . Add a temporal analytic function.
- C . Scale out the query by using PARTITION BY.
- D . Convert the query to a reference query.
- E . Increase the number of streaming units.
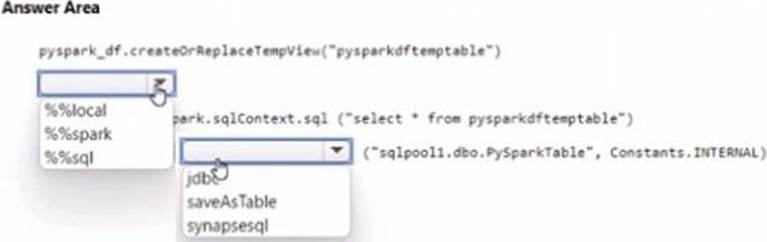
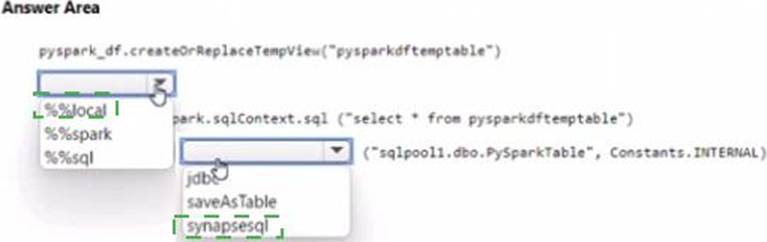
HOTSPOT
You have an Azure subscription that contains an Azure Synapse Analytics workspace named workspace1. Workspace1 contains a dedicated SQL pool named SQL Pool and an Apache Spark pool named sparkpool. Sparkpool1 contains a DataFrame named pyspark.df.
You need to write the contents of pyspark_df to a tabte in SQLPooM by using a PySpark notebook.
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have an Azure Synapse Analytics workspace named WS1 that contains an Apache Spark pool named Pool1.
You plan to create a database named D61 in Pool1.
You need to ensure that when tables are created in DB1, the tables are available automatically as external tables to the built-in serverless SQL pod.
Which format should you use for the tables in DB1?
- A . Parquet
- B . CSV
- C . ORC
- D . JSON
You are developing an application that uses Azure Data Lake Storage Gen 2.
You need to recommend a solution to grant permissions to a specific application for a limited time period.
What should you include in the recommendation?
- A . Azure Active Directory (Azure AD) identities
- B . shared access signatures (SAS)
- C . account keys
- D . role assignments
You have an Azure subscription that contains the resources shown in the following table.
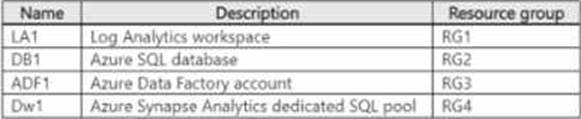
Diagnostic logs from ADF1 are sent to LA1. ADF1 contains a pipeline named Pipeline that copies data (torn DB1 to Dw1.
You need to perform the following actions:
• Create an action group named AG1.
• Configure an alert in ADF1 to use AG1.
In which resource group should you create AG1?
- A . RG1
- B . RG2
- C . RG3
- D . RG4
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
Table1 contains the following:
✑ One billion rows
✑ A clustered columnstore index
✑ A hash-distributed column named Product Key
✑ A column named Sales Date that is of the date data type and cannot be null
Thirty million rows will be added to Table1 each month.
You need to partition Table1 based on the Sales Date column. The solution must optimize query performance and data loading.
How often should you create a partition?
- A . once per month
- B . once per year
- C . once per day
- D . once per week